I'm building a geospatial data pipeline with Google Cloud Platform. My exposure to GCP is minimal as I grew up in the AWS world. It's been a breath of fresh air to have a new take on cloud computing.
The Problem
I have a nationwide (continental US) dataset of polygons. The order of magnitude is 10s of millions. My org needs to run complex queries across this dataset, but only after adding key characteristics that are derived from heterogeneous data sources: Shapefiles, GeoTIFF, CSV...to name a few. At scale, I expect the data to be < 100 TB.
Goals
- Cheap - compute is on-demand, storage is little to no cost
- Fast - Distributed data processing
- Idempotent - I can tweak logic and re-run with no worries
Solution
After evaluating a few options from AWS & GCP, I settled on GCP as my cloud provider. BigQuery is a polished product that enables non-engineer folk to get at the data they need and a pricing model that won't break the bank at a startup. How to get that data into BigQuery? Enter the data pipeline.
Getting data into BigQuery
- Upload data source to GCS (equivalent of AWS S3)
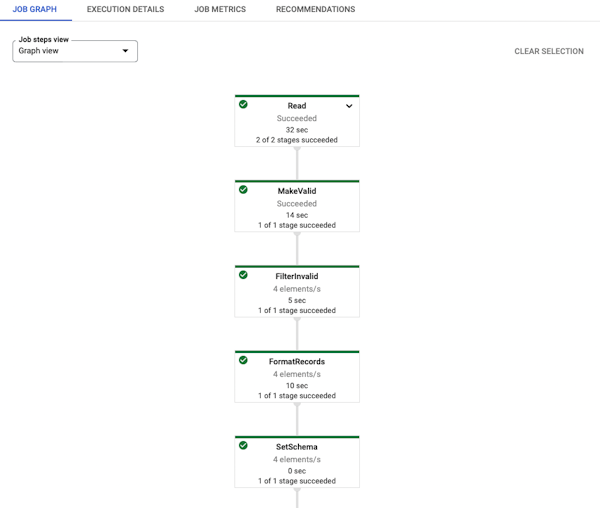
- Create Apache Beam(s) for ETL processing
- Run beam in Google Dataflow
There are a lot of spatial capabilities that Geobeam doesn't support, primarily for raster analysis. I'll add some future highlights once I have that piece of the puzzle worked out.